Berkeley AI Research (BAIR), CA, U.S.
Research Assistant • Spring 2024 - Spring 2026
With: Gopala Anumanchipalli
Kan Jen Cheng 鄭堪任
I am an incoming PhD student in Computer Science at the University of Maryland, College Park (Fall 2026), advised by Professor Ming C. Lin. Previously, I received my bachelor's degree from UC Berkeley, where I worked on audio-visual research in Berkeley Speech Group (BAIR), advised by Professor Gopala Anumanchipalli.
My research interests lie at the intersection of audio-visual learning, multimodal perception, and generative modeling. While recent advancements in LLMs have mastered language, I view text as a reduction of reality. Instead, I aim to build multimodal systems that perceive the world through the synergy of sight and sound, grounded in spatial awareness and physical understanding.
If you would like to discuss my research or potential collaborations, feel free to contact me. I'm always open to connect and collaborate.

My work is driven by two core philosophies: human-centered perception, where I model speech characteristics, affective dynamics, and joint cognitive attention to capture how humans naturally experience the world; and creative media, where I develop tools that offer precise, object-level control for content creation.
As an audio-visual researcher, I have witnessed the power of multimodal synergy, yet I realize that correlation alone is insufficient. True perception requires understanding the physical laws, such as geometry, dynamics, and material interactions, that govern the spaces where sight and sound coexist. Consequently, my future research will focus on spatial and physical learning to contribute to the development of a comprehensive world model. I aim to move beyond surface-level alignment to construct digital twins that not only mimic the appearance of the environment but also simulate its underlying physical reality. By grounding audio-visual generation in these physical truths, we can enable agents to reason about the world through a unified sensory experience.


A realization of human's audio-visual selective attention that jointly emphasizes the selected object visually and acoustically based on flow-based Schrödinger bridge.
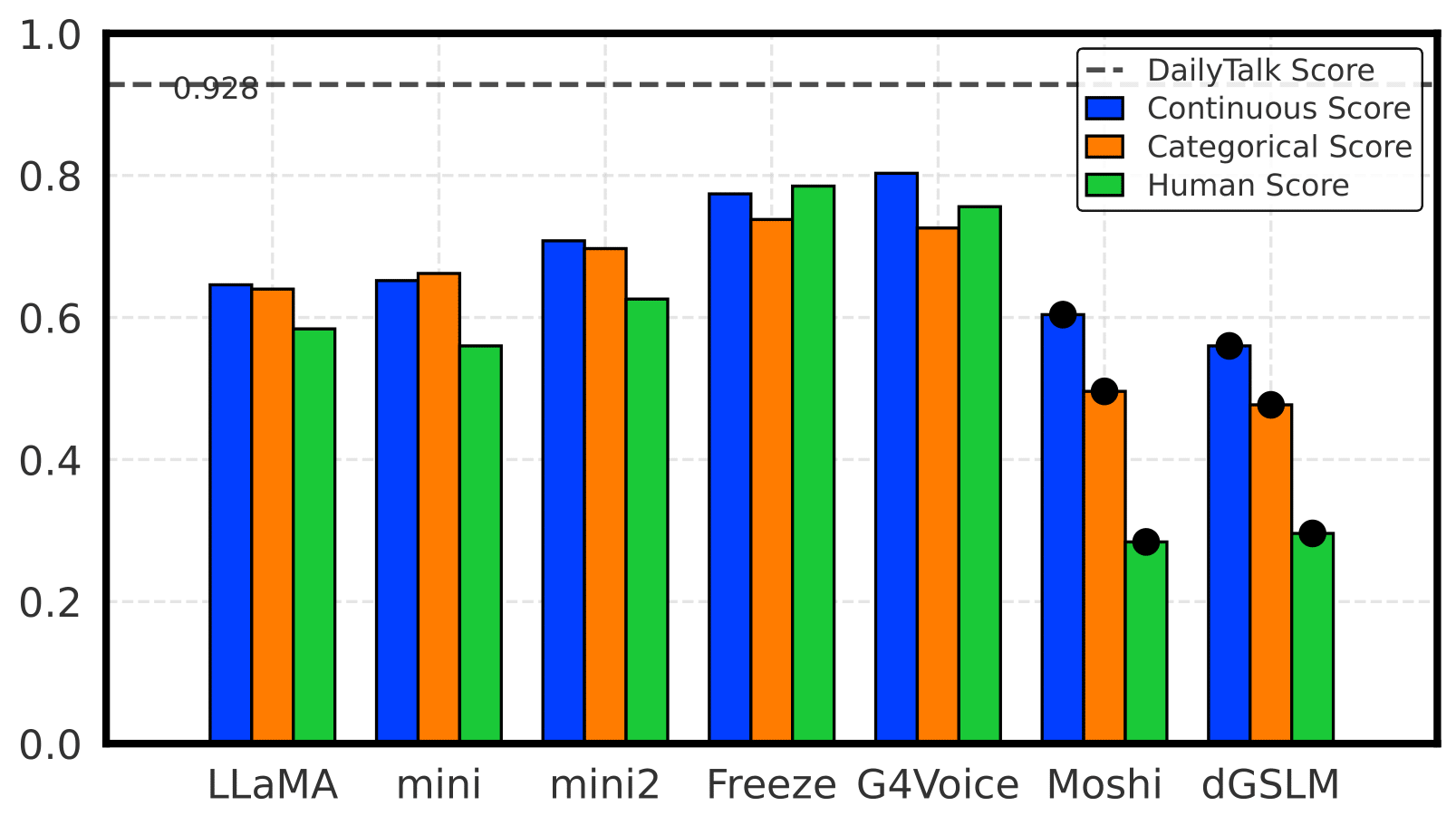
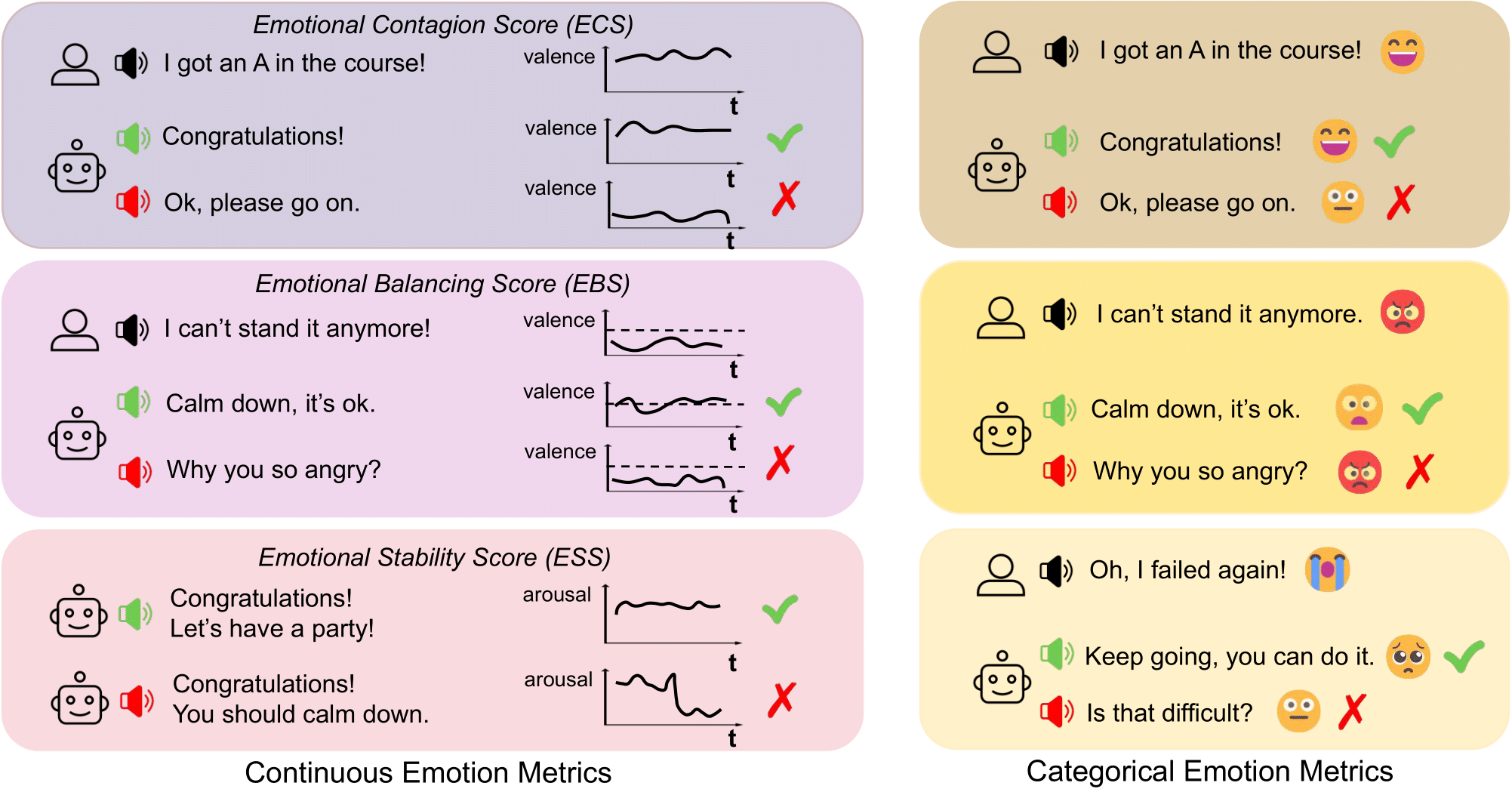
A holistic benchmark for assessing emotional coherence in spoken dialogue systems through continuous, categorical, and perceptual metrics.

A latent diffusion, exemplar-based analogy (In-Context Learning) model for audio texture manipulation, which refers to editing the overall perceptual quality of a sound and its interaction with various sound sources.
Berkeley AI Research (BAIR), CA, U.S.
Research Assistant • Spring 2024 - Spring 2026
With: Gopala Anumanchipalli
Fall 2026 - Present
University of Maryland, College Park, MD, U.S.
Ph.D. in Computer Science

Fall 2020, Spring 2022 - Fall 2023
University of California, Berkeley, CA, U.S.
B.A. in Computer Science
